音频编码 && 视频编码
音频编码
声音的本质
声音是由物体振动产生的,借助声波进行传播。
人耳的听力范围大概是20~20kHZ,即使在这个范围内,人耳朵对不同频率感觉到的不同声压db(用分贝来衡量)敏感度不同。(著名的等响曲线)
声音的三要素为:频率、振幅、波形
- 频率:代表音阶的高低,频率高,音调也高,声音尖锐;反之,频率低,音调也低,声音低沉。同时,频率(过零率)决定了波长,波长随频率的增加而减少,波长长更容易绕过障碍物,衰减小,传播距离远,反之亦然。
振幅:表示质点离开平衡位置的距离,代表了响度,我们常用分贝为单位来衡量
声音大小即
音量,与声源振幅有关,声波的震动使气压起伏称为声压。声压大,声音强,声压小,声音就弱。音色:即每种声波的波形不同。每种声音都有自己基本的波形,称为基波。不同声音的基波中混入的谐波有多有少,导致音质变化多端,也就是音色的不同。基波中混入的谐波越多,也就是泛音越多,听起来就更悦耳。高频的泛音多,声音则变得沉重、庄严、厚实。
数字音频
为了将我们听到的模拟信号转为数字信号即AD转换,需要经过采样、量化和编码
- 采样:即在时间轴上对信号进行数字化,即抽取某点的频率值,根据奈奎斯特定理,一次震动中至少要2个点的采样才能复原波形,因为人耳最高频率为20KHZ,所以至少进行40kHZ的采样频率。比如我们常见的CD,采样率为44.1KHZ。
- 量化:采样大小.在采样后,需要将该采样点的值量化,表示信号强度。比如常见的
CD为16bit的采样大小。 编码:根据采样率和采样大小可以知道,对于自然界的信号,音频编码只能做到无限接近而无法还原(目前技术是这样)。目前计算机中,能达到的高水品保真的就是
PCM(Pulse Code Modulation)编码.因此,PCM代表了最高保真水平,也就成了无损压缩。无损并不是绝对的,只能做到最大程度的无限接近而已
PCM和码率
描述一段PCM(脉冲编码调制)需要以下几个值: 量化格式、采样率、声道数
例如CD音质(wav文件):量化格式(采样大小)16bit、采样率为44.1K、声道数为2,以此来描述音质。
我们常用数据比特率(码率)来描述其音频单位时间内容量大小,对于CD音质:44.1K×16×2 =1411.2 Kbps。而其1411.2 Kbps/8 = 176.4KB/s即每秒钟需要176.4KB每分钟需要10.3M这需要存储空间太大了,因此需要各种压缩方案
我们常说128K的MP3,其对应的WAV就是这个1411.2Kbps
编码格式
压缩编码原理
因为例如CD音质 其存储空间要求太高,因此需要压缩编码。其基本指标之一就为压缩比
- 无损压缩:指解压缩之后数据可以完全复原
- 有损压缩:使用较多,在解压缩复原后会丢失一部分信息,压缩比越小,丢失信息越多,失真就会越大。
数据=信息+数据冗余
压缩编码原理其实是 压缩掉冗余信号,冗余信号指的是不能被人儿感知的信号,包括人耳听力范围以外,以及被掩蔽的信号。
掩蔽效应主要包括:频域掩蔽效应和时域掩蔽效应
频谱掩蔽效应
一个频率的声音能量小于某个阈值之后,人耳就会听不到,这个阈值称为最小可闻阈。
当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,即所谓的掩蔽效应
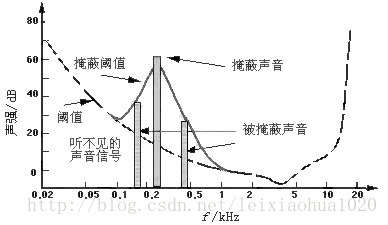
由图中我们可以看出人耳对2KHz~5KHz的声音最敏感,而对频率太低或太高的声音信号都很迟钝,当有一个频率为0.2KHz、强度为60dB的声音出现时,其附近的阈值提高了很多
如果0.1KHz~1KHz范围内的声音信号的强度在被提升的阈值曲线之下,由于它被0.2KHz强音信号所掩蔽,那么此时我们人耳只能听到0.2KHz的强音信号而根本听不见其它弱信号,这些与0.2KHz强音信号同时存在的弱音信号就可视为冗余信号而不必传送。时域掩蔽效应
当强音信号和弱音信号同时出现时,还存在时域掩蔽效应。即两者发生时间很接近的时候,也会发生掩蔽效应。
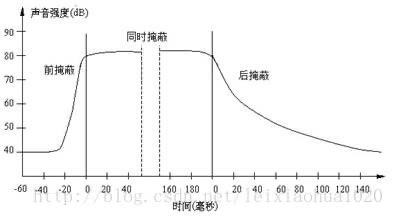
a) 前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到
b) 同时掩蔽是指当强信号与弱信号同时存在时,弱信号会被强信号所掩蔽而听不到
c) 后掩蔽是指当强信号消失后,需经过较长的一段时间才能重新听见弱信号,称为后掩蔽
这些被掩蔽的弱信号即可视为冗余信号PCM编码
优点是音质好,缺点是体积大
WAV格式
这是微软开发的一种文件格式
WAV也可以使用多种音频编码来压缩其音频流,不过我们常见的都是音频流被PCM编码处理的WAV,但这不表示WAV只能使用PCM编码,MP3编码同样也可以运用在WAV中
基于PCM编码的WAV是被支持得最好的音频格式,本身可以达到较高的音质的要求。因此,WAV也是音乐编辑创作的首选格式,适合保存音乐素材。因此,基于PCM编码的WAV被作为了一种中介的格式,常常使用在其他编码的相互转换之中,例如MP3转换成WMA。
MP3
目前最普及的音频压缩格式。在中高码率MP3文件听上去非常接机WAV文件。
优点:音质在128Kbit/s 表现不错,压缩比高,大量软件和硬件都支持
OGG
Ogg Vorbis是高质量的音频编码方案,官方数据显示:Ogg Vorbis可以在相对较低的数据速率下实现比MP3更好的音质
支持多声道(MP3只能编码2个声道)
但是目前还没有媒体服务软件支持,无法实现数字广播(流媒体),可以适用于语音聊天的音频消息
ACC
在小于128Kbit/s表现优异,多用于是偶那种的音频编码
图像编码(采样)
彩色图像记录的格式,常见的有RGB、YUV、CMYK等
RGB颜色编码
在图像显示中,一张1280 * 720大小(宽高)的图片,就代表着它有1280 * 720个像素点。
例如RGBA_8888,其中8bit表示一个子像素,因此,对于1280 * 720图像,位图大小(在内存中占用的大小)为1280 * 720 * 4 = 3.15 MB。这个内存占用是很大的,不适合在网络上传输,因此有了图像压缩,PNG/JPEG等。
但是这种压缩不适合于视频压缩,因为视频还需要考虑时域因素需要考虑。也就是不仅需要考虑帧内编码还要考虑帧间编码
YUV颜色编码
“Y”表示明亮度(Luminance、Luma),“U”和“V”则是色度、浓度(Chrominance、Chroma)。Y和色度信号UV是分离的。
Y'UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠.
色度为颜色的两个方面:色调和饱和度,分别用
Cr(RGB输入新信号红色部分和亮度值之间的差异)和Cb(RGB输入新信号蓝色色部分和亮度值之间的差异)表示
YUV Formats分成两个格式:
- 紧缩格式(packed formats): 将Y、U、V值存储成
Macro Pixels数组,和RGB的存放方式类似 - 平面格式(planar formats):将Y、U、V的三个分量分别存放在不同的矩阵中
紧缩格式中的YUV是混合在一起的,对于YUV4:4:4格式而言,用紧缩格式很合适的,因此就有了UYVY、YUYV等。平面格式是指每Y分量,U分量和V分量都是以独立的平面组织的,也就是说所有的U分量必须在Y分量后面,而V分量在所有的U分量后面,此一格式适用于采样。平面格式有I420(4:2:0)、YV12、IYUV等。
常用YUV抽样
图像的Y、U、V颜色分量

最常用的YUV均用一个字节即8位表示
为节省带宽起见,大多数YUV格式平均使用的每像素位数都少于24位。
- 4:4:4表示完全取样。
- 4:2:2表示2:1的水平取样,垂直完全采样
- 4:2:0表示2:1的水平取样,垂直2:1采样
- 4:1:1表示4:1的水平取样,垂直完全采样
最常用Y:UV记录的比重通常1:1或2:1,最常用的为YUV 4:2:0即I420。YUV4:2:0并不是说只有U(即Cb), V(即Cr)一定为0,而是指U:V互相援引,时见时隐,也就是说对于每一个行,只有一个U或者V分量,如果一行是4:2:0的话,下一行就是4:0:2,再下一行是4:2:0...以此类推
YUV转换为RGB
渲染在屏幕上的东西,都必须转换为RGB形式,而在传输图像数据时又是使用 YUV 模型,这是因为 YUV 模型可以节省带宽。因此就需要采集图像时将 RGB 模型转换到 YUV 模型,显示时再将 YUV 模型转换为 RGB 模型。
视频编码
数字化后的视频信号进行压缩主要依据:
- 数据冗余:例如如空间冗余、时间冗余、结构冗余、信息熵冗余等,即图像的各像素之间存在着很强的相关性。消除这些冗余并不会导致信息损失,属于无损压缩。
- 视觉冗余:人眼的一些特性比如亮度辨别阈值,视觉阈值,对亮度和色度的敏感度不同,使得在编码的时候引入适量的误差,也不会被察觉出来。可以利用人眼的视觉特性,以一定的客观失真换取数据压缩。这种压缩属于有损压缩。
一般数字视频压缩都是混合编码,即将变换编码、运动估计和运动不长以及熵编码三种方式结合来进行压缩编码
压缩编码方式
变换编码
变换编码来消去除图像的帧内冗余
因为一般图像在空间上有很强的相关性,将空间域描述的图像信号变换到频率域,可以实现区相关和能量集中。信号经过DCT变换(离散余弦变换)为频率域后需要进行量化。
因为人眼对图像的低频特性比如物体的总体亮度之类的信息很敏感,而对图像中的高频细节信息不敏感,因此在传送过程中可以少传或不传送高频信息,只传送低频部分。量化过程通过对低频区的系数进行细量化,高频区的系数进行粗量化,去除了人眼不敏感的高频信息,从而降低信息传送量。因此,量化是一个有损压缩的过程,而且是视频压缩编码中质量损伤的主要原因。
熵编码
熵编码通常来进一步提高压缩的效率
熵编码是因编码后的平均码长接近信源熵值而得名。熵编码多用可变字长编码(VLC,Variable Length Coding)实现。其基本原理是对信源中出现概率大的符号赋予短码,对于出现概率小的符号赋予长码,从而在统计上获得较短的平均码长。
运动估计和运动补偿
用运动估计和运动补偿来去除图像的帧间冗余,消除图像序列时间方向相关性的手段。
DCT变换、量化、熵编码是在一帧图像的基础上进行,消除空间上的相关性。
实际上图像信号除了空间上的相关性之外,还有时间上的相关性,可以只对相邻视频帧中变化的部分进行编码,从而进一步减小数据量,这方面的工作是由运动估计和运动补偿来实现的。
运动估计技术一般将当前的输入图像分割成若干彼此不相重叠的小图像子块,然后在前一图像或者后一个图像某个搜索窗口的范围内为每一个图像块寻找一个与之最为相似的图像块。这个搜寻的过程叫做运动估计。
通过计算最相似的图像块与该图像块之间的位置信息,可以得到一个运动矢量。
将当前图像中的块与参考图像运动矢量所指向的最相似的图像块相减,得到一个残差图像块,由于残差图像块中的每个像素值很小,所以在压缩编码中可以获得更高的压缩比。这个相减过程叫运动补偿。
IPB
编码过程中需要使用参考图像来进行运动估计和运动补偿,因此参考图像的选择显得很重要。一般情况下编码器的将输入的每一帧图像根据其参考图像的不同分成3种不同的类型:I(Intra)帧、B(Bidirection prediction)帧、P(Prediction)帧
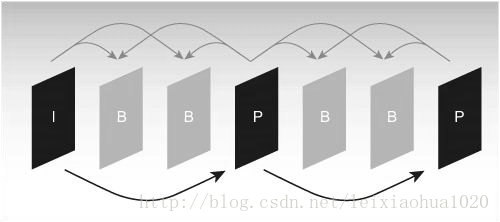
IPB是常见的帧压缩方法,其中I帧属于关键帧是每个画面的参考帧;P帧是前向预测帧,B帧时双向预测帧。
所以I帧很关键,压缩I帧泳衣压制掉空间大小,压缩P/B帧可以压缩掉时间上的冗余信息。所以,在视频seek时,I帧很关键,如果视频seek之后发生往前的跳动,那可能是视频压缩的太厉害了
IDR帧:因为H264采用多帧预测,导致I帧不能作为独立的观察条件,所以多了一个叫IDR帧的特殊I帧作为参考,IDR帧关键概念是:==解码过程中 一旦收到IDR帧就清空参考帧缓冲区,并将IDR帧作为被参考帧
DTS(Decoding Time Stamp) && PTS(Presentation Time Stamp):DTS主要用于视频的解码 PTS主要用于解码阶段对视频进行同步或输出
GOP(group of picture) 就是两个I帧之间的距离,一般GOP设置的越大,画面效果就会越好,需要的解码时间越长。所以 如果码率固定GOP值越大,P/B帧数量越多,画面质量越好
混合编码
通常是结合起来使用以达到最好的压缩效果
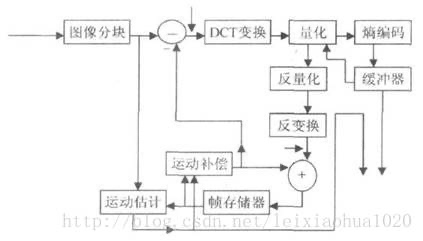
从图中我们可以看到,当前输入的图像首先要经过分块,分块得到的图像块要与经过运动补偿的预测图像相减得到差值图像X,然后对该差值图像块进行DCT变换和量化,量化输出的数据有两个不同的去处:一个是送给熵编码器进行编码,编码后的码流输出到一个缓存器中保存,等待传送出去。另一个应用是进行反量化和反变化后的到信号X’,该信号将与运动补偿输出的图像块相加得到新的预测图像信号,并将新的预测图像块送至帧存储器。